
|
29/10/2018 0 Comments What is Robotic Process Automation? Robotic process automation, or RPA for short, is an emerging technology that allows you to automate business processes. It does this by mimicking the work of one or more users. I've seen this technology running on a thin-client machine, where the aim of the original business process was to create consulting codes. The diagram below, shows a simple example of how RPA can work. If you're used simpler tools, like Flow in Office 365 of IFTTT.com then you'll be familiar with this automation concept. I use IFTTT for my social media automation: 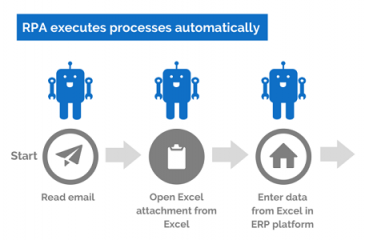 Let me back up a bit and explain RPA in the context of a real-world business problem. Consulting codes are used in many organisations. They allow consultants to book time to a client, a project or a particular type of work. These codes are usually entered into a timesheet and time is allocated against them. If you work in a medium to large organisation, you'll be familiar with the use of SAP, Dynamics 365 or other web-based timesheet programs that allow entry of timesheet information via these consulting codes. The codes are critical to ensuring that clients are billed correctly, project spend is accurately tracked and that it's clear what consultants are spending their time on. Without these codes, the business would grind to a halt, after all, not being able to invoice clients for work, is one of the most critical business processes in a business, next to paying employees and selling new products. The most common type of code I've code across, is called a Work Breakdown Structure Code (WBS). You can see them in use in SAP. The diagram below shows some of the key information that is required to build a WBS code in SAP: 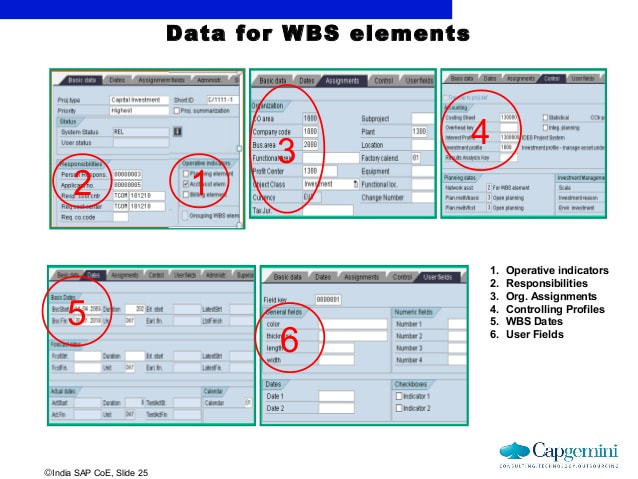 So how does this work on a thin-client PC? Well let's take Citrix XenDesktop product. Once built, installed and setup, using automation influenced by a DevOps culture, we have a small farm of virtual desktops that we can use as robots. In the WBS Code example above, we need to first understand the entire business process for creating an SAP WBS process. Below is a diagram showing how we might build the XenApp farm and build out our army of automated workers: 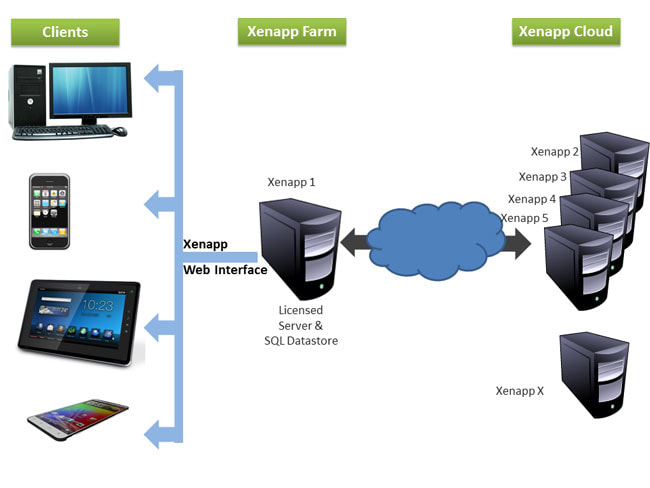 Let's assume this process requires a geographically dispersed team, spread across Australia, India and Malaysia and involved 5 handoffs. That is 5 different people that need to do something in the process. It's likely we're going to have some lost time, whilst we wait for the next person to do something. In fact I've seen this process take up to 5 days, when in fact, once all the data is known, it should only take 30 minutes. The key here is that it is often the waiting time in a process, that slows things down. In other words, we're waiting on the next person in the process to do something. If they're busy this delay may only be a few hours. Worse case they may be on leave, which means there maybe a much longer delay. This is because it may take a few hours or days for someone to actually come to that item in their queue and process the transaction. So clearly there is a driver for improved customer service, by using an automated process to remove these delays. Below is a diagram that illustrates a sample business process. It outlines the process of making a pizza. As you can see it contains a number of handoffs. These delays between handoffs will affect the speed at which the pizza is delivered to the end-customer: 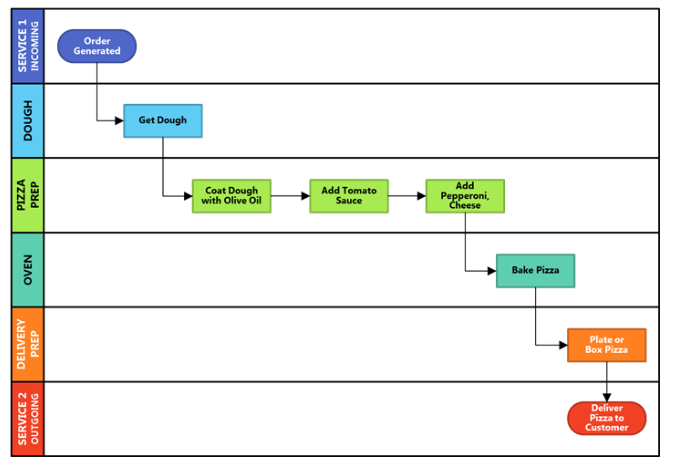 The next step, once you have understood your process and you know what each person does at each step, you can now setup your 3 virtual desktops with all the software, the same as your workers. It also may be possible at this stage to install all the software on a single virtual desktop and think about streamlining your process. So let's assume we are able to do this and stay with a single virtual desktop. Once the desktop is setup, we can then use the in-built RPA engine to create the automation and store this as code. This means we can view the code and optimise as required. Here is a video which provides an introduction to building RPA automation using a product called Blue Prism. I've chosen this product, because I've seen this working on the SAP WBS code automation problem. We're using the process studio function to build our automation. www.youtube.com/watch?v=AhUojgE3WUI 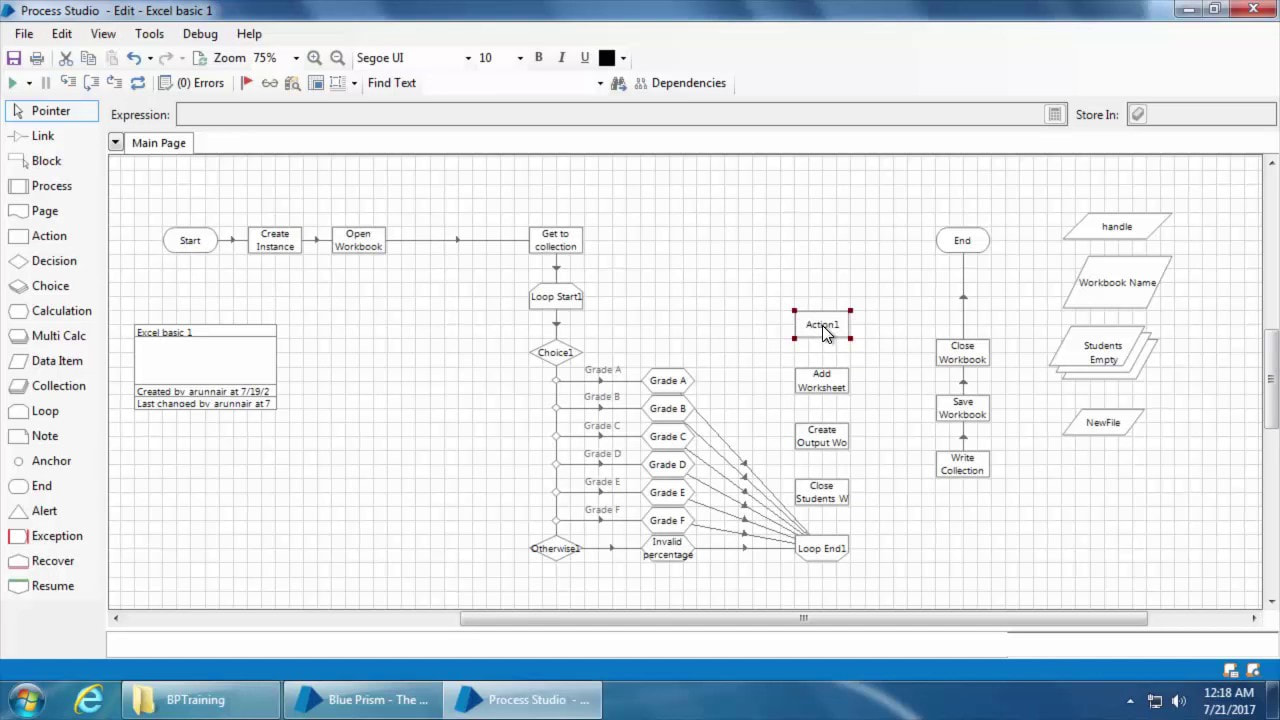 Clearly there are a few techniques within a product like Blue Prism for automating processes. I've shown you the 'process studio' technique as it's very visual and simple to understand.
For more information on how to automate processes as part of a DevOps culture change program, it would be worth considering our DevOps Foundation courses. We outline the basic principles of cultural change and discuss how tools, such as Blue Prism, Jenkins, DXC Agility, GitHub, .Net framework and many other tools, can help improve the quality and speed of your solution release lifecycle: www.alctraining.com.au/courses/devops/
0 Comments
There is often a lot of confusion around the differences between machine learning and deep learning. Both are classed as techniques to enable artificial intellgence or AI. But what is AI? AI is the ability to create a program or computer system that can fool a human into thinking it is another human. There is a simple test for this called the Turing Test, developed by Alan Turing. Turing is a famous computer scientist who is potrayed in the film 'The Imitation Game'. He was the UK's secret weapon in the 2nd World War. The test is very simple. There are 3 actors. A computer, person B and our interrogator C. Each actor is placed a separate room. If the interrogator is unable to determine which actor is the computer, then the computer is determined to be intelligence, albeit it's artificial. Here is a simple diagram outlining this concept: 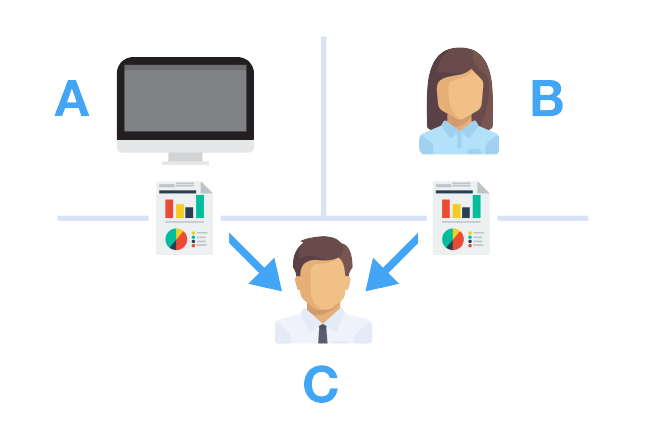 Coming back to the machine learning and deep learning techniques, let's define those in turn. We can use either or both techniques to fool our interrogator into thinking our computer is intelligent. Deep Learning - is the process of applying neural network theory to help a computer learn. Neural network theory strives to mimic our brain function. Our brains are made of neurons and pathways, known as neural networks. With deep learning we setup virtual neurons and virtual gateways in our system and use similar biological rules to allow the network to start learning. In order to understand neural networks in more detail, you'll need to cover some psychobiology theory that outlines how the brain works. Here is a simple video on how neurons work: www.youtube.com/watch?v=vyNkAuX29OU The diagram below shows some of the many possible neural networks that you can choose from: 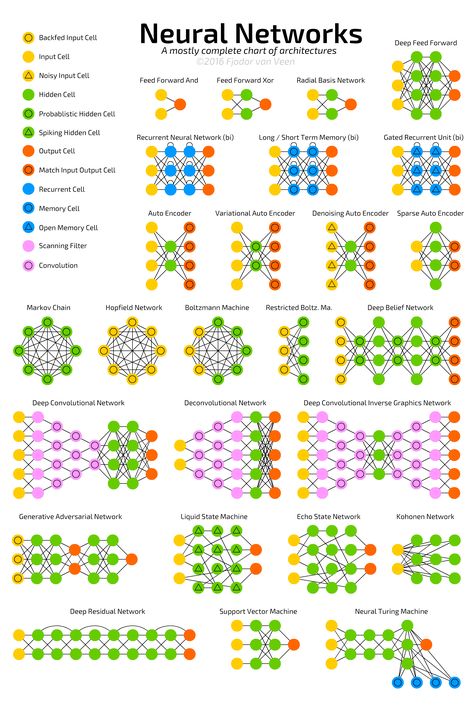 Machine Learning - is the process of applying mathematical models to help a computer learn. It does not attempt to mimic the brain in terms of structure, but instead provides a process for allowing a computer to learn via mathematical techniques. There are 100's of mathematical methods to enable machine learning. Some examples include: random forest, regression and dedcision trees. Here is a great example of a decision tree: 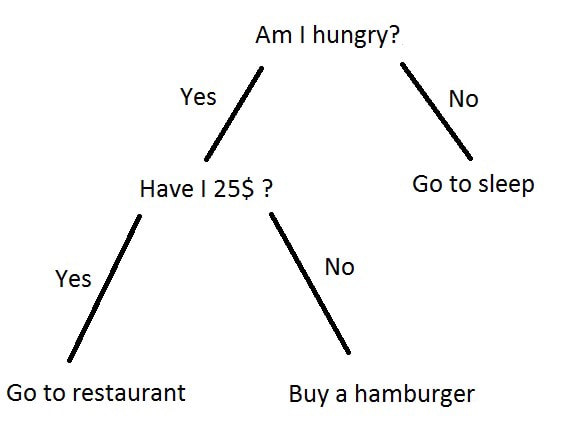 And finally to put things in context, we can see how AI, Machine Learning and Deep Learning has evolved over time in the diagram below. This is also a differentiator between machine learning and deep learning. As you can see deep learning is a newer technique, inspired by human biology, whereas machine learning is an older technique, inspired by various mathematicians: 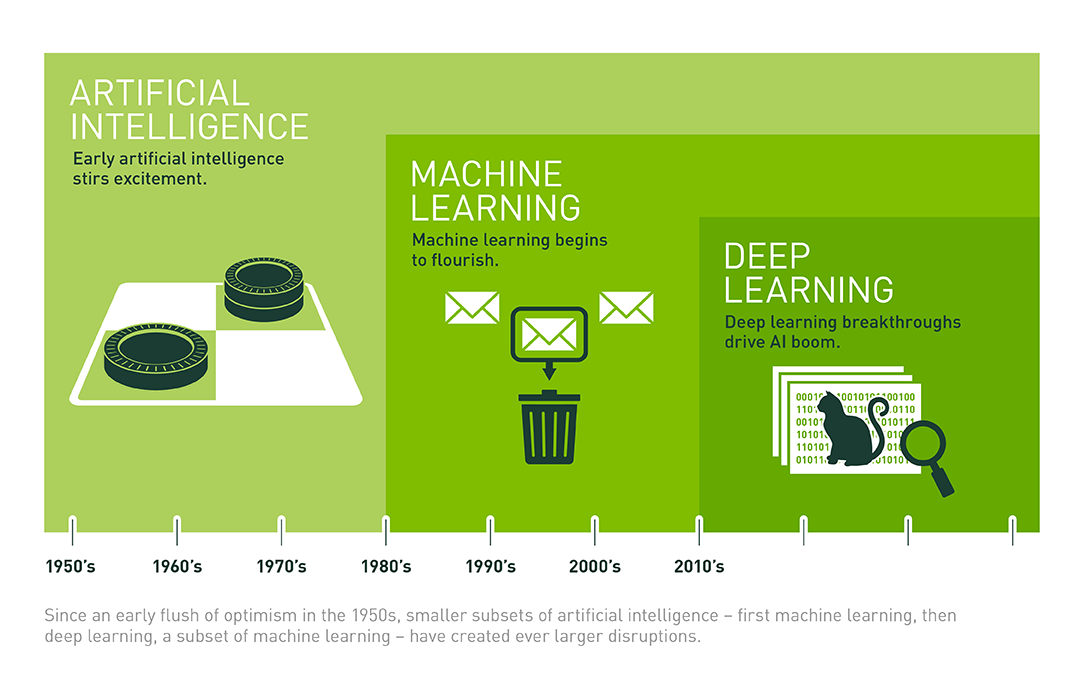 Check out the Nvidia blog that accompanies the picture...BTW....they provide the deep learning framework for Tesla cars....
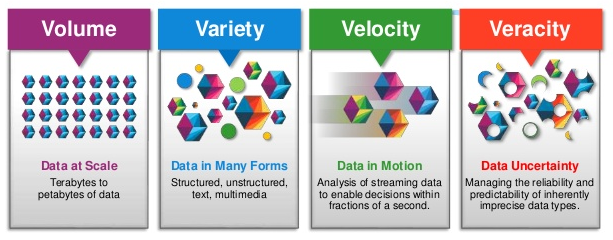
blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/ As you can see, the biggest challenge that a data scientist has to content with, is which deep learning or machine learning technique to use. That's of course once we have a clearly defined business requirement and/or outcome we're looking for and we've probably spend days or months trying to obtain clean data. Oh the joys of data science..... I was very fortunate in 2011 to be awarded a Leading Edge Forum Grant to perform distinguished research on In-Memory Data Grid technologies (IMDG). At the time, the term Big Data had not been coined, or at least I had never heard of it. The 3 months of intensive study and research for the CSC Leading Edge Forum, now known as DXC Technology, lead to a path of self-discovery and a realisation of what was really happening in the data space. Here is a link to the brochure showcasing my work: www.slideshare.net/CSC/csc-grants-via-leading-edge-forum  Big Data is now defined as the problem space, relating to the cleaning and analysis of huge data sets, resulting in a series of recommendations, a roadmap and/or defined business outcomes. It's further described by using the 4 V's:
 Based on my research, and because of my classical / jazz composition background, I see Big Data slightly differently. You see when I studied musical composition at the University of Wales and the London College of Music, I learnt that the most talented composers and performers had been using the same system for around 500+ years. Sounds remarkable, that a single system would pervade for so long, but it's true. We call it tonality, or in laymans terms we use keys and scales in music. When we learn to play a musical instrument we learn all the different scales and all the different keys. Examples include C Major, D minor, B flat major or C# minor. This is why there is much emphasis on practicing scales and chords. This system is called the tonal system and is still strongly used in pop music culture, especially in the pop music charts. Now...at the turn of the century, between 1900 and 1925 a group of composers emerged, that are now called the Second Viennese School. And what they did was remarkable. They pretty much started to reject the use of the tonal system, that had served mankind well for 500+ years and created a new form of music called serialism. Simply put, that is music that does not have a tonal centre, a key or is not strictly part of a scale. We describe this as atonalism. To the untrained ear, it would appear that the notes seems to be random and dissonant. This is what atonal music, using serialism composition can look like.  You'll see that every note on the top stave is never repeated and every note on the bottom stave is also never repeated. This ensures that no note takes precedence and stops us perceiving any form of tonal centre, or tonality. Below is a short video explaining serialism, if you're interested in learning more. www.youtube.com/watch?v=c6fw_JEKT6Q This new school of serialism, led by Schonberg, Webern and Berg, was mirrored in the art and fashion worlds, through the abstract art movement, with Jackson Pollock being the most famous. Below is an example of Pollock's work:  So what the hell does this have to do with Big Data, I hear you cry? Well Big Data is a great analog of this short history lesson in modern musical composition theory. We've been using relational datastores for 30 years, and apart from the emergence of a few exceptions, the most popular datastores have been SQL based, conforming to relational database theory. These datastores are commonly known as relational database management systems or RDBMS. Think of relational database theory as musical tonal theory. It's worked for a long time, so why change it? Examples of RDBMS include Microsoft SQL, Oracle and SAP. With a relational datastore, we store data in tables and these tables all relate to each other in a schema. Below is a simple example: 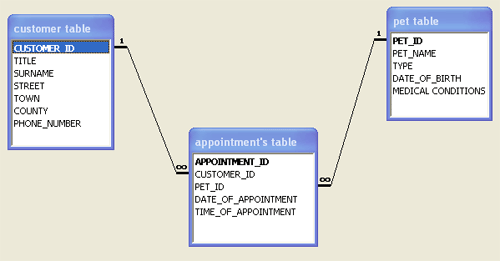 : There are other rules that need to be implemented in order for a relational datastore and these include following the ACID principles, and rationalising the structure using normal forms. Here is a good article outlining relational database theory: en.wikipedia.org/wiki/Relational_database Then companies decided to rethink the storage of data, to help solve new, complex problems. The challenge with relational datastores is that they are great at storing customer information and financial information, but are not very good at processing and storing millions of records, that are unstructured, with 1000s of additional unstructured data items being thrown into the mix per second, with varying levels of data quality. Basically relational datastores are not built to cope with Big Data. They tend to be much slower, reliant on ACID principles, and are not optimised for handling unstructued or semi-structured data. The diagram below outlines ACID principles in an RDBMS architecture: 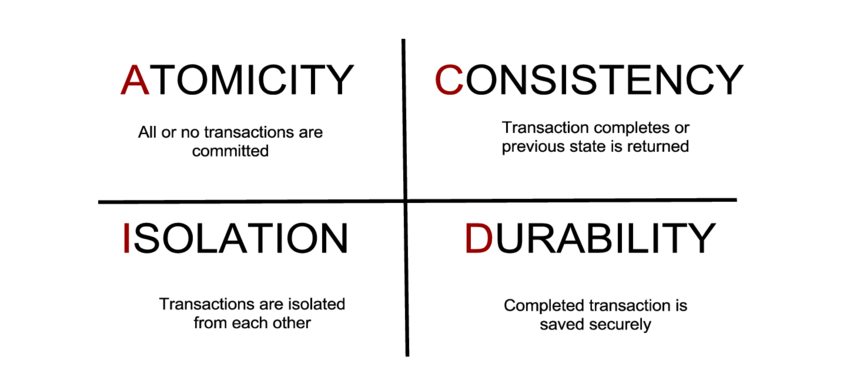 The first well known company to use non-relational datastores en-mass was Napster. They created a peer-to-peer music sharing network in the early 2000's and used distributed hash tables to link up the data via central servers. A distributed hash table is essentialy a key value store, which links a key (name of the song and artist), with a value (a link to the mp3 file). This means it's super fast and able to reference unstructured data very efficiently. This provided a very successful, timely and ground-breaking music streaming service, similar to Spotify today. In those days Napster was later shown to be an illegal service, which has since reached agreements with record companies and artists. Click on the diagram below to view a short video outlining how Peer to Peer networks operate: 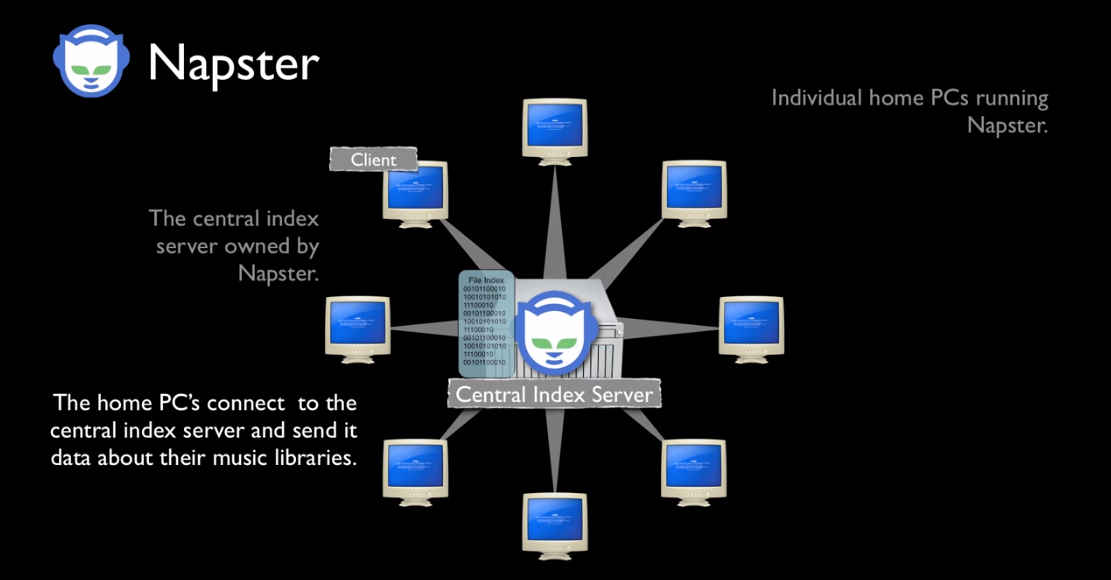 In parallel we see Google invent Apache Hadoop technologies to deal with vast quantities of indexing material for search engines and the Big Data ecosystem grows expotentially from there. We now have NOSQL datastores, In-Memory Data Grids and the list goes on. Here is an article that best describes the key differences between the most common types of technology: NOSQL, RDBMS and Hadoop: www.datasciencecentral.com/profiles/blogs/hadoop-vs-nosql-vs-sql-vs-newsql-by-example Be aware that there is huge complexity and variation between different types of Big Data products. The diagram illustrates this point, by outlining the current Hadoop suite of software tools, that can be utilised in a Big Data initiative. 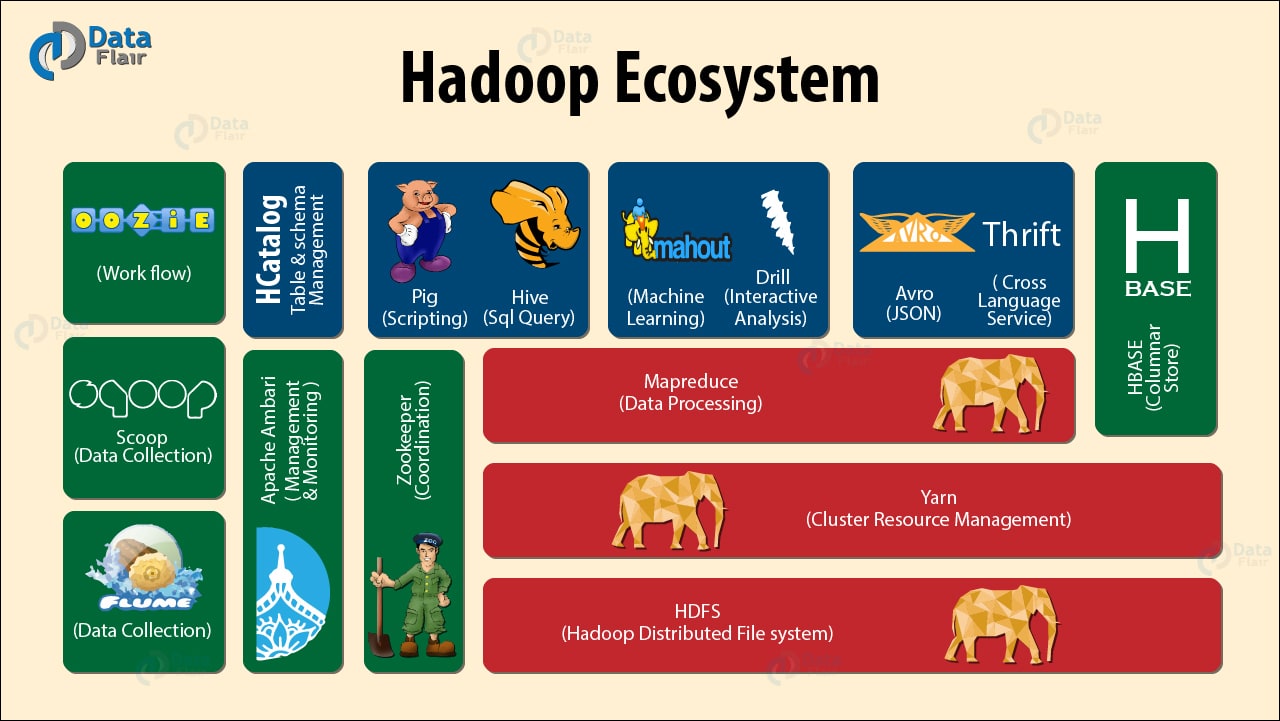 Unfortunately we haven't had enough time to cover Artificial Intelligence, Machine Learning and Deep Learning, which I'll save for another blog post. But these techniques, methods, approaches are all part of the Big Data movement. If you're interested in learning more about Big Data technologies, check out our range of Cloud courses, where understanding RDBMS, NoSQL and Hadoop is key to utilising Amazon Web Services and Microsoft Azure cloud services. www.alctraining.com.au/courses/cloud-computing/ We'll be realising details of our Enterprise Big Data Professional certification within the coming weeks, so watch this space:  |
CategoriesAll Active Directory AI Architecture Big Data Blockchain Cloud Comedy Cyber DevOps Driverless Cars MicroServices Office 365 Scaled Agile Social Media 
AuthorPaul Colmer is an AWS Senior Technical Trainer. Paul has an infectious passion for inspring others to learn and to applying disruptive thinking in an engaging and positive way. Archives
May 2023
|
 RSS Feed
RSS Feed